NCC is developed by Nutanix Engineering from inputs provided by support engineers, customers, on-call engineers and solution architects. Nutanix Engineering productised their troubleshooting scripts into NCC. Nutanix Cluster health runs NCC plugins at various intervals and provides easy access to the results through UI. Nutanix customer will be able troubleshoot or identify the issues with the cluster and will result in a faster resolution. This will provide uniform troubleshooting tools across different Hypervisors.
Nutanix cluster health can be accessed from Prism Element (URL: CVM's ip address).
 | |||
| Prism Element First Page - Cluster Health Access |
Here is the list of cluster health checks
 |
| List of Health Check |
CVM: -
- CPU Utilization/Load Average
- Disk - Metadata Usage (Inode)/HDD disk Usage (df) /HDD latency(sar/iostat) smartctl status/SSD latency.
- Memory committed ( /proc/meminfo)
- Network - CVM to CVM connectivity (external Vswitch), CVM to host (nutanixVswitch), Gateway config, subnet config ( verify nutanix HA network config)
- Time Drift - between CVM/Host
- CPU utilization
- Memory swap rate
- Network - 10 Gbe connectivity(vswitch and vmknic) / Nic Error Rate/Receive and Packet loss (ethtool)
- CPU utilization
- I/O latency (vdisk)
- Memory ( swap rate/usage)
- Network Rx/Tx packet loss.
nutanix@NTNX-13SM35300008-B-CVM:10.1.60.110:~$ ncli health-check ls |grep Name
Name : I/O Latency
Name : CPU Utilization
Name : Disk Metadata Usage
Name : Transmit Packet Loss
Name : CVM to CVM Connectivity
Name : Receive Packet Loss
Name : CPU Utilization
Name : CPU Utilization
Name : Transmit Packet Loss
Name : Memory Usage
Name : Receive Packet Loss
Name : HDD I/O Latency
Name : Gateway Configuration
Name : HDD S.M.A.R.T Health Status
Name : Load Level
Name : Memory Usage
Name : CVM to Host Connectivity
Name : 10 GbE Compliance
Name : Time Drift
Name : HDD Disk Usage
Name : SSD I/O Latency
Name : Memory Pressure
Name : Memory Swap Rate
Name : Subnet Configuration
Name : Memory Swap Rate
Name : Node Nic Error Rate High
Name : I/O Latency
Name : CPU Utilization
Name : Disk Metadata Usage
Name : Transmit Packet Loss
Name : CVM to CVM Connectivity
Name : Receive Packet Loss
Name : CPU Utilization
Name : CPU Utilization
Name : Transmit Packet Loss
Name : Memory Usage
Name : Receive Packet Loss
Name : HDD I/O Latency
Name : Gateway Configuration
Name : HDD S.M.A.R.T Health Status
Name : Load Level
Name : Memory Usage
Name : CVM to Host Connectivity
Name : 10 GbE Compliance
Name : Time Drift
Name : HDD Disk Usage
Name : SSD I/O Latency
Name : Memory Pressure
Name : Memory Swap Rate
Name : Subnet Configuration
Name : Memory Swap Rate
Name : Node Nic Error Rate High
Configuration of Health Checks:

- Turn Check off
- Parameters for Critical/Warn Threshold (if applicable)
- Change the schedule.
- Edit option available from CLI as well . ncli health-check edit (interval/enable/parameter-thresholds)

Each health check provides
- Cause of the failure : Example - disk running out of space
- Resolution: How to fix the issue -Example: add storage capacity or delete the data.
- Impact: What will be the user/cluster impact ?

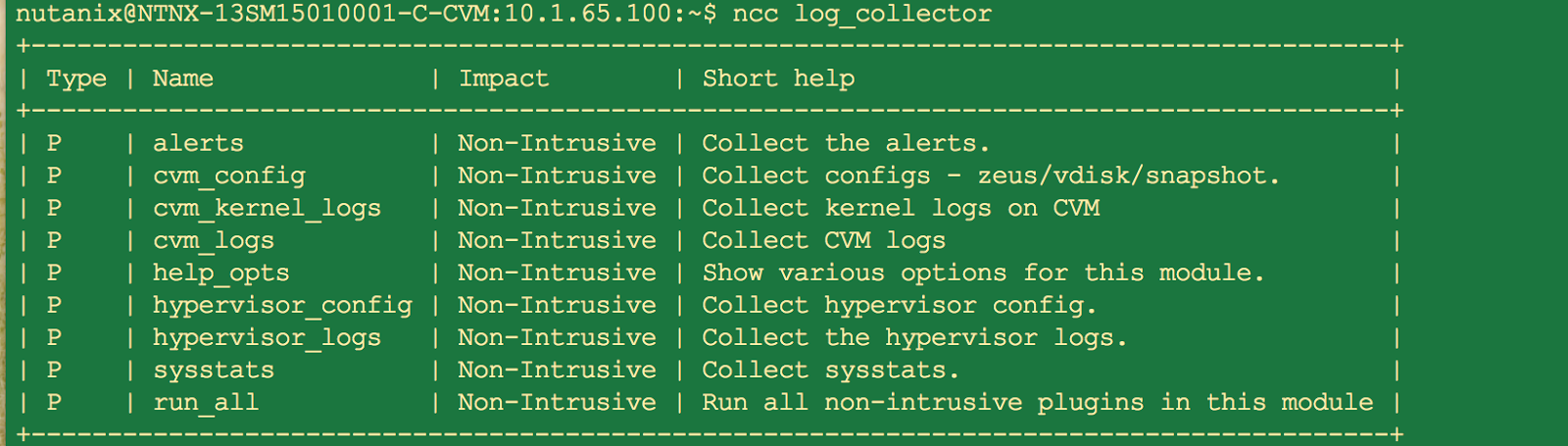
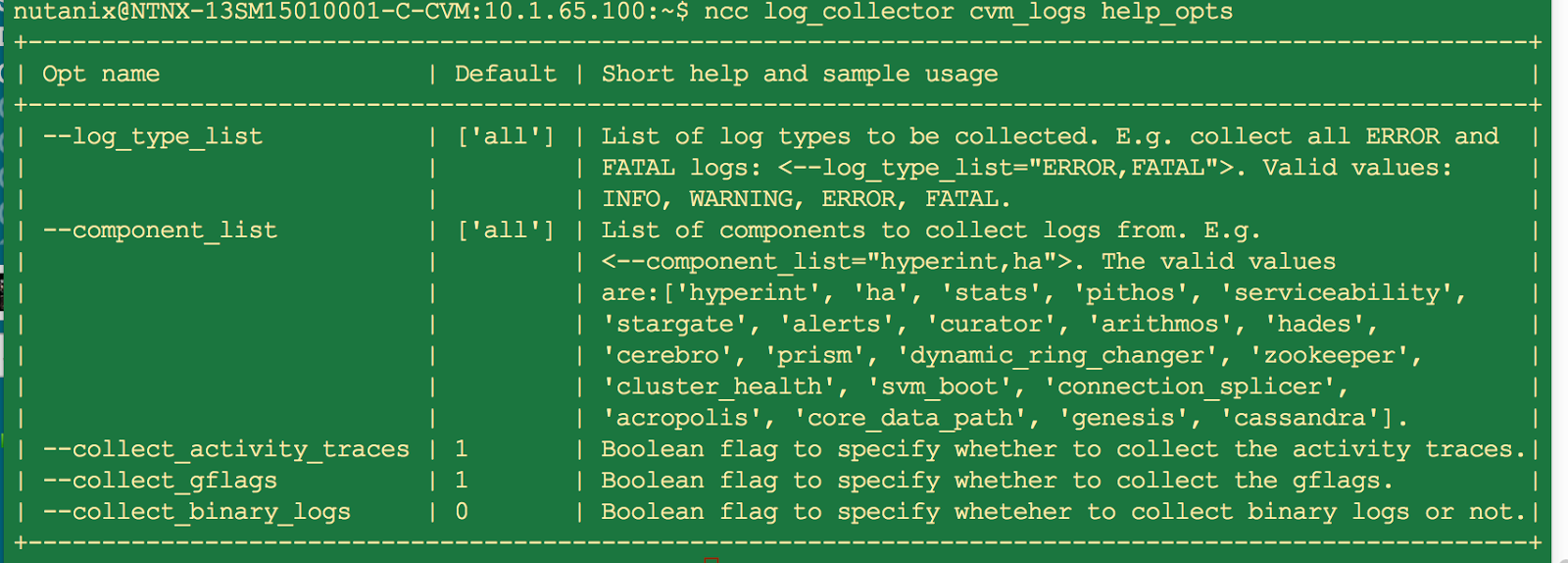
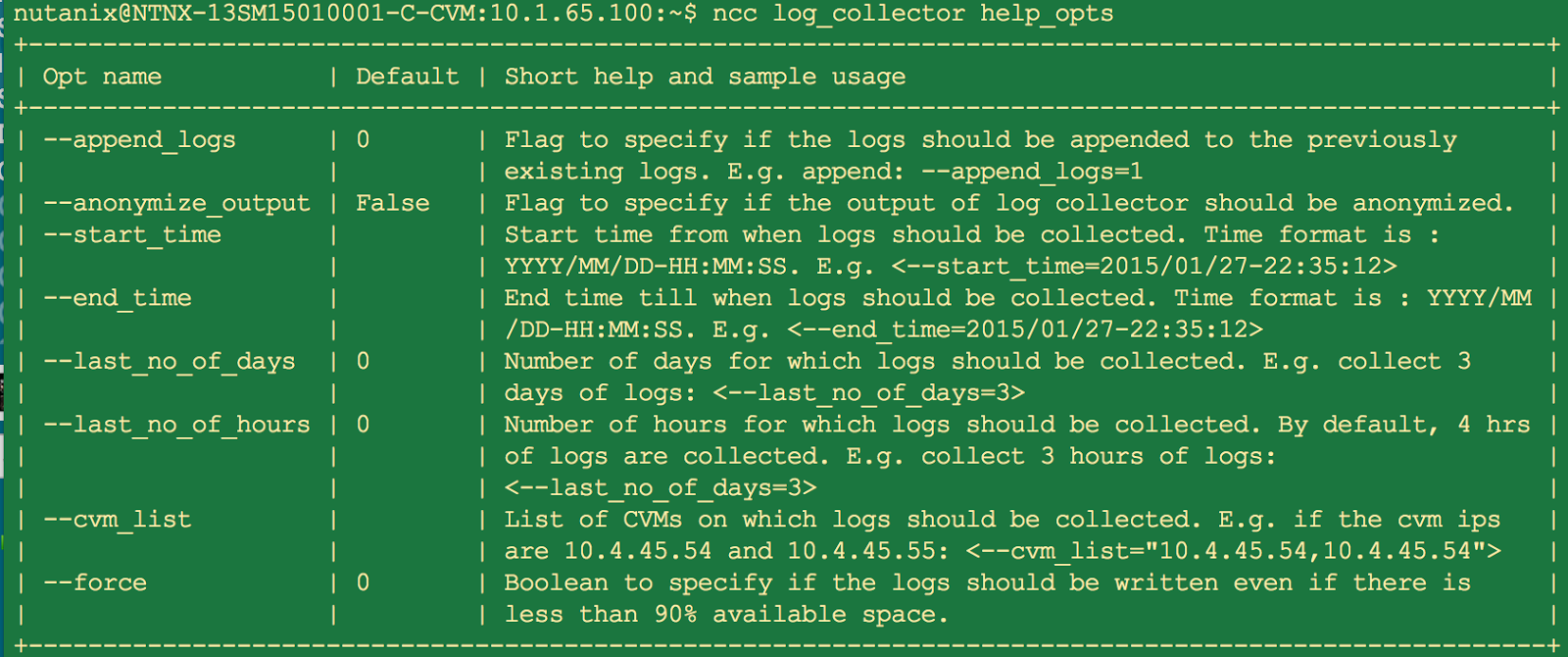
Running the plugin manually:
NCC is superset of health check and has more plugins that can be run. NCC can be updated independently of NOS versions. ( note that the certain newer NCC plugins may be applicable only to certain NOS versions). Here are sample of few NCC options.
![]()
Future Developments:
![]() Here are some of the feedback that we got about our first version of "cluster health". We will continue to improve the user experience as well as add more checks.
Here are some of the feedback that we got about our first version of "cluster health". We will continue to improve the user experience as well as add more checks.
![]()
NCC is superset of health check and has more plugins that can be run. NCC can be updated independently of NOS versions. ( note that the certain newer NCC plugins may be applicable only to certain NOS versions). Here are sample of few NCC options.
 |
| ncc health check |
List of Network Checks that can be run ( intrusive checks will affect the performance of the cluster.)
 |
| ncc network_checks |
Sample of running a network_check .

- Unification of Cluster health, Alerts and Events.
- Impact, Cause and Resolution updated via NCC updates independent of NOS upgrade.
- Provide finer Root Cause analysis and more insights into cluster health.